
Imagínese sentado relajado en el sofá y simplemente ordenando a su computadora o computadora portátil o teléfono celular realizar tareas simples como escribir una letra o ejecutar algunos comandos. ¿Es posible?
Por supuesto que lo es, ahí es donde entra en escena el reconocimiento de voz.
Siguiendo la definición, es el proceso de reconocimiento del habla humana y descodificación en forma de texto.
Principio
El principio básico de reconocimiento de voz Implica el hecho de que el habla o las palabras pronunciadas por cualquier ser humano provocan vibraciones en el aire, conocidas como ondas sonoras. Estas ondas continuas o analógicas se digitalizan y procesan y luego se decodifican en palabras apropiadas y luego en oraciones apropiadas.

Componentes de un sistema de reconocimiento de voz
Entonces, ¿en qué consiste un sistema básico de reconocimiento de voz?

- Un dispositivo de captura de voz : Consiste en un micrófono, que convierte las señales de ondas sonoras en señales eléctricas y un Convertidor Analógico a Digital que muestrea y digitaliza las señales analógicas para obtener los datos discretos que la computadora puede entender.
- Un módulo de señal digital o un procesador : Realiza el procesamiento de la señal de voz sin procesar, como la conversión del dominio de frecuencia, restaurando solo la información requerida, etc.
- Almacenamiento de señales preprocesadas : La voz preprocesada se almacena en la memoria para realizar más tareas de reconocimiento de voz.
- Patrones de habla de referencia : La computadora o el sistema consta de patrones de voz predefinidos o plantillas ya almacenadas en la memoria, que se utilizarán como referencia para la coincidencia.
- Algoritmo de coincidencia de patrones : La señal de voz desconocida se compara con el patrón de voz de referencia para determinar las palabras reales o el patrón de palabras.
Funcionamiento del sistema
Ahora veamos cómo funciona realmente todo el sistema.

- Una voz puede verse como una forma de onda acústica, es decir, una señal que lleva información de mensaje. Un ser humano normal con la velocidad limitada de movimiento de sus articuladores (órganos del habla) puede producir el habla a una velocidad promedio de 10 sonidos por segundo. La tasa de información promedio es de 50 a 60 bits / segundo. Significa que en realidad solo se requieren 50 bits / segundo de información en la señal de voz. Esta forma de onda acústica se convierte en señales eléctricas analógicas mediante el micrófono. El convertidor de analógico a digital convierte esta señal analógica en muestras digitales al tomar medidas precisas de la onda a intervalos discretos.
- La señal digitalizada consiste en un flujo de señales periódicas muestreadas a 16000 veces por segundo y no es adecuada para realizar reconocimiento de voz proceso ya que el patrón no se puede localizar fácilmente. Para extraer la información real, la señal en el dominio del tiempo se convierte en una señal en el dominio de la frecuencia. Esto lo hace el procesador de señal digital utilizando la técnica FFT. En la señal digital, el componente después de cada 1/100thde segundo se analiza y se calcula el espectro de frecuencia para cada componente. En otras palabras, la señal digitalizada se segmenta en pequeñas partes de amplitudes de frecuencia.
- Cada segmento o gráfico de frecuencia representa los diferentes sonidos que hacen los seres humanos. La computadora realiza la correspondencia de los segmentos desconocidos con la fonética almacenada del idioma en particular. Esta coincidencia de patrones se realiza de 3 formas:
Usando un enfoque fonético acústico : En el enfoque fonético acústico, generalmente se utiliza el modelo de Markov oculto. Este modelo desarrolla un modelo de probabilidad no determinista para el reconocimiento de voz. Este modelo consta de dos variables: los estados ocultos de los fonemas almacenados en la memoria de la computadora y el segmento de frecuencia visible de la señal digital. Cada fonema tiene su propia probabilidad y el segmento se empareja con el fonema de acuerdo con la probabilidad y los fonemas coincidentes se recopilan para formar las palabras correctas de acuerdo con las reglas gramaticales almacenadas del idioma.
Usando un enfoque de reconocimiento de patrones : En el enfoque de reconocimiento de patrones, el sistema se entrena con un patrón de voz particular para cualquier idioma y el patrón de voz desconocido se compara con el patrón de voz de referencia determinando la distancia entre las señales utilizando la técnica de distorsión del tiempo.
Usando inteligencia artificial : El enfoque de la Inteligencia Artificial se basa en la utilización de fuentes de conocimientos básicos, como el conocimiento de los sonidos hablados sobre la base de medidas espectrales, el conocimiento de las palabras significativas y sintácticas adecuadas.
Factores de los que depende el sistema de reconocimiento de voz
El sistema de reconocimiento de voz depende de los siguientes factores:
- Palabras aisladas : Debe haber una pausa entre las palabras consecutivas habladas porque las palabras continuas pueden superponerse, lo que dificulta que el sistema comprenda cuándo comienza o termina una palabra. Por lo tanto, debe haber un silencio entre palabras consecutivas.
- Altavoz único : Muchos oradores que intentan dar entrada de voz al mismo tiempo pueden provocar la superposición de señales e interrupciones. La mayoría de los sistemas de reconocimiento de voz utilizados son sistemas dependientes del hablante.
- Tamaño del vocabulario : Los idiomas con un vocabulario extenso son difíciles de considerar para la coincidencia de patrones que aquellos con vocabulario pequeño, ya que las posibilidades de tener palabras ambiguas son menores en este último.
Sistema de reconocimiento de voz en Windows 7
Me gustaría recomendar los siguientes pasos para cualquier persona que use Windows 7 para el sistema de reconocimiento de voz
- Abra el Panel de control desde el menú de inicio o haciendo clic en el icono.
- Seleccione Facilidad de acceso y luego haga clic en Reconocimiento de voz.
- A continuación, haga clic en configurar micrófono y seleccione el micrófono de escritorio de las opciones disponibles.
- A continuación, tome el tutorial de voz y siga las instrucciones dadas.
- Después de eso, entrene su computadora para mejores opciones de modo que la computadora almacene un patrón definido de su señal de voz. Esto se hace haciendo clic en la opción 'entrenar a su computadora para que lo comprenda mejor' y luego siga las instrucciones.
- Ahora inicie el icono de reconocimiento de voz y comience a dictar su voz a la computadora. También puede agregar sus propias palabras al diccionario de la computadora.
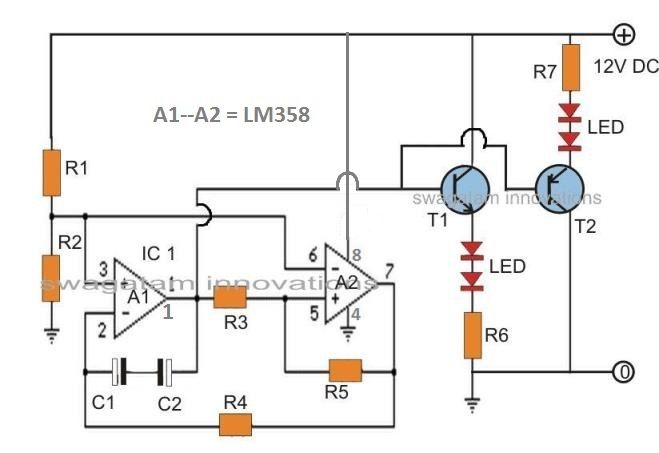
Sistemas prácticos de reconocimiento de voz: uso de HM2007
Se puede construir un sistema de reconocimiento de voz práctico utilizando IC de reconocimiento de voz HM2007 . El HM2007 es un IC de 48 pines que proporciona una función de reconocimiento de voz. Funciona en dos modos: modo manual o modo CPU. En ambos modos, el IC es entrenado primero para reconocer palabras por el usuario que dice cada palabra para el número correspondiente presionado en la tecla. El IC almacena cada señal de palabra en la ubicación de memoria correspondiente a la palabra. La salida de datos del IC se interconecta con el microcontrolador desde donde se muestra en la pantalla LCD.

Normalmente utilizamos el modo manual para el funcionamiento del HM2007.
- El HM2007 consta de un pin RDY que es un pin activo bajo que indica que el IC está listo para fines de entrenamiento.
- La entrada de voz se dará a través de un micrófono conectado al pin MICIN del IC.
- El IC está interconectado con un teclado que se utiliza para proporcionar la entrada numérica correspondiente a cada palabra. El IC funciona en dos funciones: despejar y entrenar. Cuando se presiona la tecla Train en el teclado, el IC comienza su proceso de entrenamiento.
- El usuario presiona una tecla numérica antes de presionar la tecla de función 'Entrenar' y dice la palabra requerida al micrófono.
- El IC envía una señal alta al pin ME (Memory Enable) que está conectado al pin ME correspondiente de SRAM. La señal de datos de 8 bits correspondiente al número pulsado se almacena en la SRAM (RAM externa) a través del bus externo.
- Después de que se detecta la entrada de voz, el pin RDY está en lógica alta y el IC llega al estado de reconocimiento, donde comienza el proceso de reconocimiento.
- El resultado del proceso se da a través del bus de datos con el pin DEN (Data Enable) alto.
- Luego, los datos de 8 bits se pueden entregar al microcontrolador a través de un procesador de interfaz en serie o se pueden enganchar primero usando el CI 74HC573.
- El microcontrolador está interconectado con una pantalla LCD y está programado de manera que la palabra correspondiente se muestre en la pantalla.
La única precaución que se debe tomar es no usar homónimos (palabras con sonido similar) y también cuidar la excitación en la voz.
Entonces, así es como sistema de reconocimiento de voz básico trabajos. Se pueden agregar más aportaciones.
Credito de imagen
Componentes del sistema de reconocimiento de voz mediante una introducción al reconocimiento del habla y del hablante: Richard D. Peacocke y Daryl H. Graf





{kind=link}